Source codes teach us almost everything we need to know about catalog circulation. What exactly do we learn from source codes?
- The relative performance of each mailing list segment.
- The performance of each mailing or catalog event
- The value of a customer over its lifetime by the original source or mailing list.
- The time needed to break even on a first-time customer if the list segment didn’t breakeven on the initial mailing.
- The value of different groups of catalog requests.
Knowing the performance of each list segment is important because the key to circulation planning is to prospect at breakeven and make your profits from mailing your buyers. If you mail too much circulation below breakeven, you drain cash and eventually go out of business. Understanding the performance of each individual list segment mailed allows you to stop mailing the unprofitable segments and to continue mailing and expand the circulation of profitable segments.
The basic information that source codes track includes sales, the number of orders, the response rate, the average order and the total dollars from each list segment. The most important metric is the sales per book (SPB), which is the total revenue from each list segment divided by the circulation mailed. Sales per book tells at a glance whether the list segment yielded sales above or below breakeven.

To compare a mailing to other mailings or other new customer acquisition efforts (pay-per-click, e-mails, affiliate marketing, space advertising, etc.) take the basic sales data and extend the financials from top line sales-per-book to bottom line profitability.
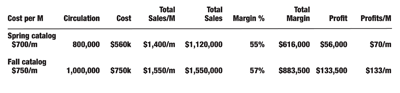
So from tracking the sales of two different catalogs with slightly different costs, sales per book and margin, you can see the relative profitability of the two different mailings. Some mailers also take the analysis of each individual list segment mailed.
Smart marketers have a system in which the initial key code is maintained for each customer throughout its entire life cycle on the customer file. Keeping source codes for the life of the customer allows a cataloger to track the value of customers from the original source.
This is increasingly important, as the flow of Web orders and orders from sources other than prospecting via traditional mailing lists becomes a larger and larger part of each cataloger’s buyer file. Most marketers drop the original key code and use source codes with the age of the record last, such as three-month buyer.
While this source code methodology tracks the buyer file by recency, you lose the data about how buyers from different original sources respond to follow-up catalog mailings. If you keep original source codes, you can easily analyze the lifetime value of buyers obtained from different sources and tailor your circulation plans.
Is there a simple source code methodology? Most catalogs can use a five digit code with the first digit being the year of the mailing (6 for 2006), the second digit being the mailing that year (the second mailing of the year is 2), and the third, fourth and fifth digits being the individual list segments being mailed.
Source codes are critical to the analysis, planning and control of your catalog’s circulation. Giving a source code to each list segment mailed and to all the other types of promotions and then capturing the source codes fanatically is one of the keys to maximizing circulation profitability.
Jim Coogan is president of Santa Fe, NM-based consultancy Catalog Marketing Economics.