

Online surveys have grown in popularity because of the ease with which they give organizations valuable insights into everything from product design and packaging to consumer buying habits. But today’s research platforms often impose a tradeoff between speed and simplicity and the richness of actionable insights.
A combination of machine learning technology and crowdsourcing concepts is solving this problem. It enables researchers to shorten online survey time without having to resort to matrix tables that often make surveys uncomfortably long and can skew results. At the same time, these technologies deliver the higher accuracy, deeper insights and superior user experience of open-ended questions.
Matrix Table Challenges
Researchers have typically accelerated online surveys by asking questions not one by one but in a more space-efficient matrix format (questions are in the table’s rows, response scale options in its columns). Our study, however, shows this can skew answers to the midrange, as shown in Figure 1. It also may encourage “straight-lining” (i.e., selecting the same response for all rows of the matrix) and even prime respondents to answer in a certain way.
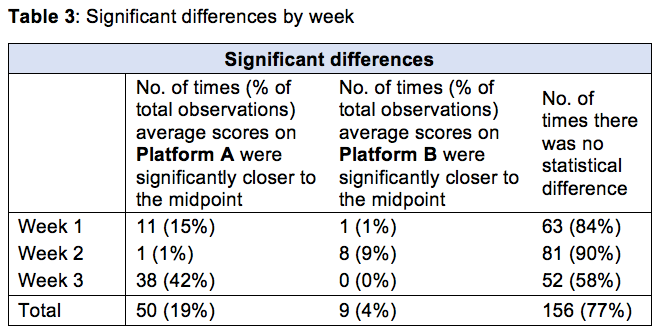
A second study we conducted tested whether this observed midpoint drift could be replicated in a different set of questions while controlling for the direction of scales, complexity of matrix attributes and length of the matrix question. Results showed that the table format does have some impact on questions that are more involved for the respondent to process. Also, when the amount of effort required for reading and comprehension was amplified, it translated into a longer amount of time spent on each matrix.
The other problem with a matrix format is that it is typically used with predetermined closed-ended questions. While most intuitively understand the benefits of open-ended questions, a big limitation has been the text box. It produces raw, unorganized data that are difficult to practically use without further cleaning and processing. Moreover, respondents often skip over them, making the researcher forgo any data from those respondents whatsoever.
This was tested with a survey we conducted evaluating user perception of several ads. Each respondent could either record unaided feedback in a text box or leave it blank, and both the quantity and quality of answers were at issue. Out of 3,061 possibly valid free text answers, only 2,243 useful answers were received, or approximately 73%. After accounting for all the blanks and useless answers, only about 25% of the answers generated by the free text box were usable.
A Better Approach
Machine learning combined with a creative respondent-engagement methodology can help ensure that the majority of an online survey’s open-ended questions deliver useful feedback. With this approach, respondents are asked for an unaided answer just as they are with traditional surveys. But then a sampling algorithm is used to present statements based on other participants’ cleaned-up answers to the same question, to which they can agree or disagree. The step is repeated five to 10 times.
This crowdsourcing of the feedback-optimization process ensures that data is acquired from all respondents, even if it is only a read on how they felt about others’ answers. This additional data contributes to much richer feedback during the ideation phase of the survey. It also improves the evaluation phase since answers have been validated by a large number of participants. There is greater confidence in the natural language answers that have been received, enabling more robust coded answers to be built than is possible with ex-post free-text analytics tools.
Answering open ends may take a little more time as participants evaluate 5 to 10 statements sampled by the system, but this only adds an average of 15 to 45 seconds to survey completion time. Meanwhile, respondents often report that they enjoy the process of evaluating others’ answers and feel more engaged than when simply filling in a simple text box.
Researchers benefit, as well. Their survey output is a cleaned, coded, and organized data set rather than a raw text file, available as soon as respondents start providing answers since the algorithm runs in real time. Additionally, the statistically validated qualitative data can be used in more traditional quantitative analyses including segmentation, pricing or NPS studies for which natural text data become categorical variables in a quantitative model.
Advances in computational technology and machine learning are pushing the research industry ever closer to meaningfully transitioning online research into a free-flowing natural conversation with the customer, at scale, while seamlessly combining open-ended and choice questions.
This approach also can effectively replace traditional table matrix questions, avoiding their limitations and letting survey participants freely ideate and validate their own hypotheses on the fly. Such unfiltered, organic voice of the customer information is simultaneously validated, labeled and organized by the underlying algorithm to make data analysis as easy as that of a traditional matrix question.
Rasto Ivanic is co-founder and CEO of GroupSolver